

Building AI Agents That Actually Troubleshoot: Lessons from Production

What 7 research papers, 3 failed architectures, and 16 real-world scenarios taught me about designing LLM-powered root cause analysis agents.
The Promise and the Reality
Everyone wants an AI agent that can diagnose production incidents autonomously. The pitch is compelling: feed it your logs, metrics, and traces, and let it find the root cause while you sleep.
The reality is sobering. Microsoft’s AIOpsLab benchmark (2024) found that current LLM agents achieve only ~18% end-to-end resolution on complex scenarios. They’re good at generating hypotheses. They’re terrible at executing multi-step investigations without losing the thread.
But between “fully autonomous” and “useless” lies a design space that actually works. After building and iterating on a troubleshooting agent for a large-scale infrastructure platform — testing against 16 real incident scenarios — here’s what we learned about what works, what fails, and why.
Why Multi-Agent Loops Fail for Troubleshooting
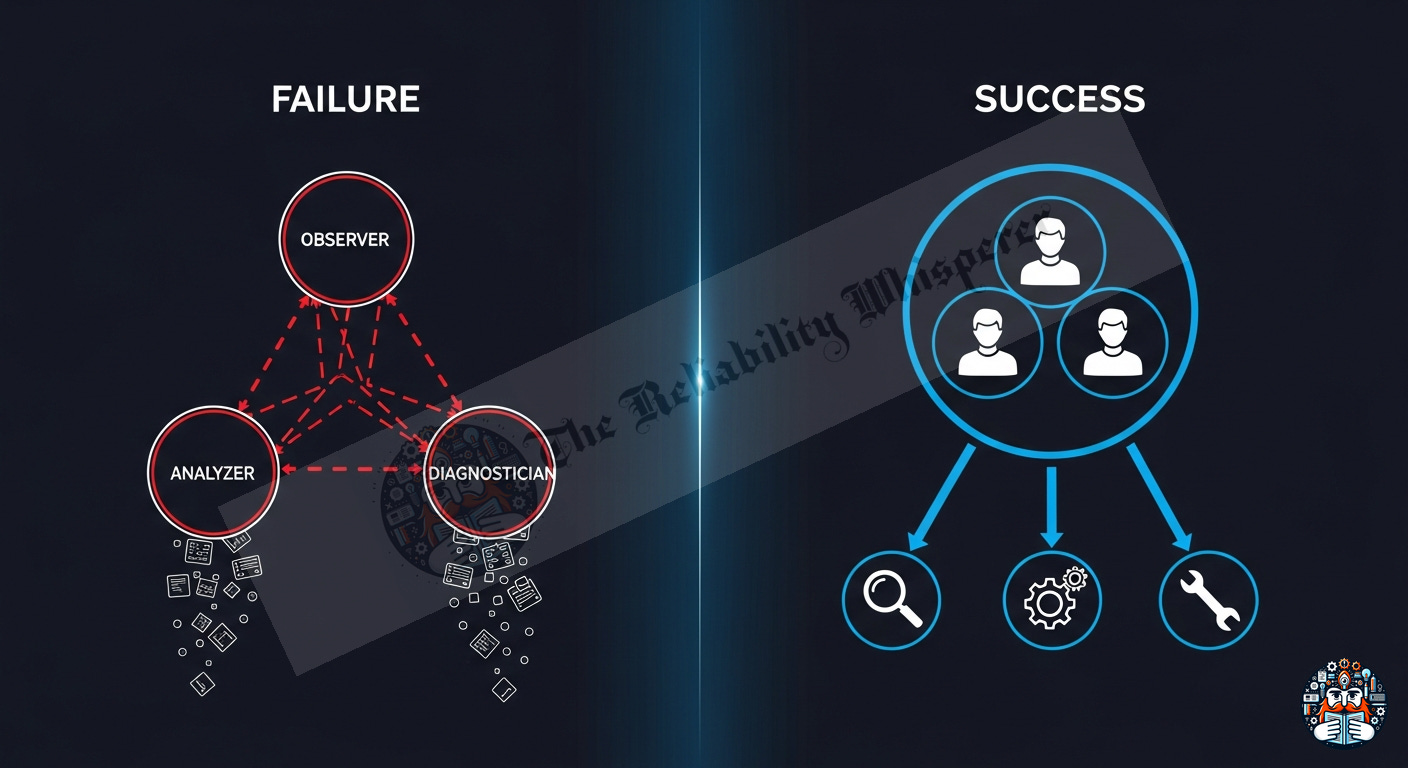
The intuitive architecture is a loop: Observer detects symptoms → Analyzer gathers data → Diagnostician evaluates findings → repeat until confident.
This is clean on a whiteboard. In practice:
Context loss between agents. Each agent in a loop starts with a fresh context. The Observer’s nuanced understanding of the problem doesn’t transfer to the Analyzer. You’re passing state through string keys — a lossy compression of reasoning.
Over-segmentation of thought. Troubleshooting is fluid. A senior engineer doesn’t stop thinking to “switch to analyzer mode.” They see a log line, form a hypothesis, query a system, and adjust — all in one continuous stream. Forcing this into discrete phases creates artificial handoffs that break reasoning coherence.
Token multiplication. Three agents × N iterations = 3N separate LLM calls. Each call re-processes the system prompt. A 3-iteration loop costs ~12,000+ tokens. A single agent doing the same work in one continuous session: ~6,300 tokens.
State propagation bugs. In frameworks like Google ADK’s LoopAgent, state written by one sub-agent isn’t always reliably available to the next. You end up debugging your debugging agent.
The Alternative That Works
One agent. All the tools. Strong instruction. The LLM iterates naturally through sequential tool calls within a single session context. No context loss. No state propagation issues. The full reasoning chain stays coherent.
This isn’t lazy engineering — it’s supported by research. IBM’s ReAct+AIOps paper (2024) found that ReAct-style loops with tools work excellently when the agent maintains context. The multi-agent overhead adds cost without adding capability for reasoning-heavy tasks.
The Architecture That Works
┌─────────────────────────────────────────┐
│ Dispatcher (router only) │
│ Classifies: simple query vs diagnosis │
└──────────┬──────────────────┬────────────┘
│ │
▼ ▼
┌──────────────┐ ┌─────────────────────────────┐
│ Simple Query │ │ Troubleshooter Agent │
│ Agents │ │ [single LLM, N tools + KB] │
│ (one-hop) │ │ │
└──────────────┘ │ • Direct tool access │
│ • Knowledge base fallback │
│ • Embedded domain rules │
│ • Circuit breaker at 12 │
└─────────────────────────────┘
The dispatcher handles routing. Simple questions (”what’s the status of X?”) go to lightweight single-tool agents. Complex diagnosis (”why is X failing?”) goes to the Troubleshooter — one agent with the full diagnostic toolkit.
Five Design Principles (Research-Backed)
1. Embed the 80%, Query the 20%
The instinct is to keep the agent “general” and have it query a knowledge base for every investigation. This wastes tool calls and adds latency.
What works: Embed deterministic diagnostic paths directly in the instruction for the most common scenarios. For a given stuck state, the first check is ALWAYS the same — hardcode it.
State: X stuck for >2 hours → First check: service A logs for specific error pattern
State: Y timeout → First check: dependency B health endpoint
State: Z authorization error → First check: config C permission field
This saves 1-2 tool calls per investigation (the “understand the system” phase). Reserve the KB query for novel scenarios that don’t match any embedded pattern.
Research basis: RCACopilot (Microsoft, ICSE 2024) found that service-specific retrieval yields 77% accuracy vs <40% for generic prompting. The embedded diagnostic table IS service-specific retrieval — just pre-computed.
2. Trace Dependencies, Don’t Check Flat Lists
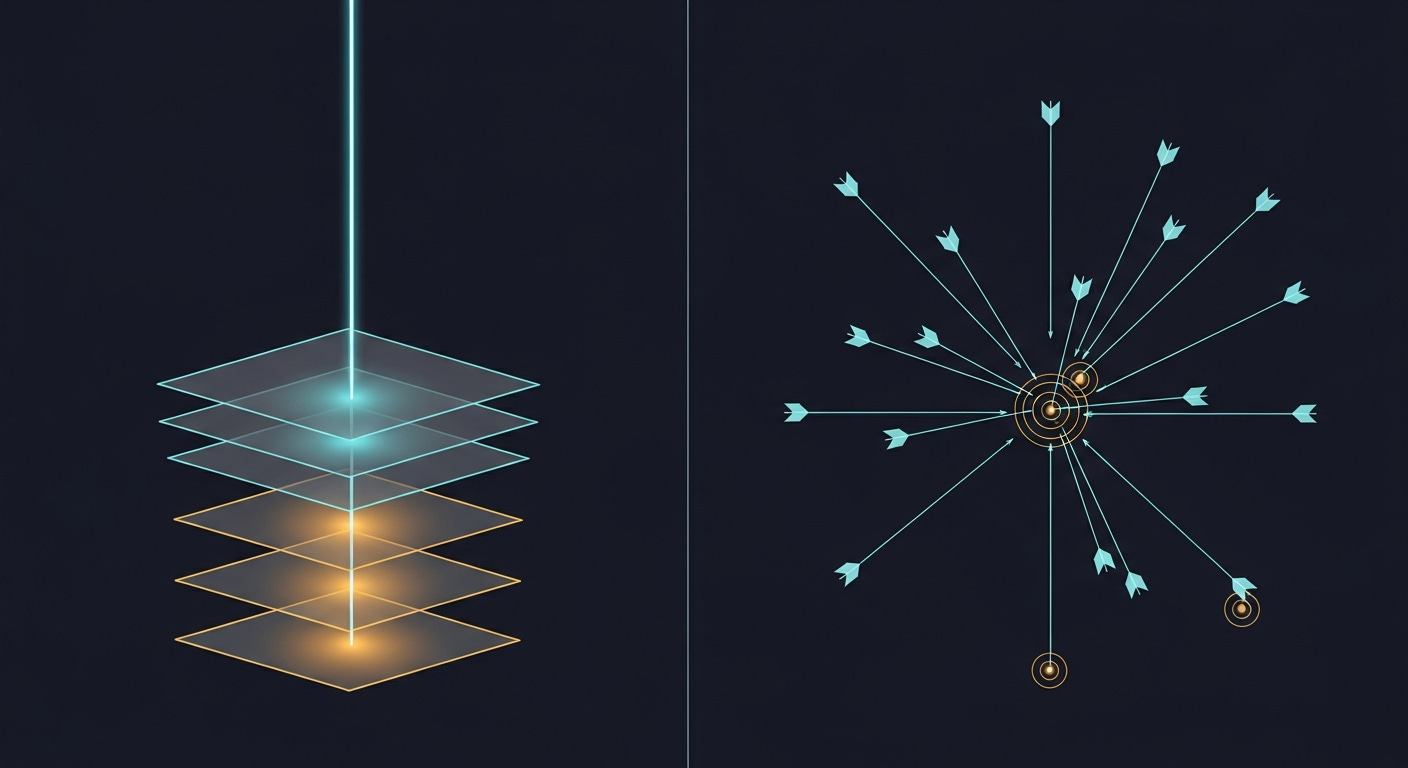
A flat requirements checklist (”check A, check B, check C, check D”) fans out into N parallel queries. This is wasteful when the actual failure is always in one specific branch.
What works: Follow the dependency chain downward. Each tool call is informed by the previous result.
System stuck
→ Query orchestrator: which gate is failing?
→ Gate = "DNS validation"
→ Check DNS: record missing
→ Check IPAM: never created
→ ROOT CAUSE: upstream config missing
Five targeted calls beats nine parallel ones. Each call narrows the scope. You find the root cause in the same number of calls regardless of how many potential causes exist.
3. Triage Before Investigating
The most expensive mistake: spending 12 tool calls investigating something that isn’t broken.
Many systems have states that LOOK stuck but are actually normal:
A firmware upgrade that takes 47 minutes isn’t stuck at 30 minutes
A grace period of 60 hours before auto-escalation means “waiting 48 hours” is expected
A service reporting “permission denied” during a gate check is expected behavior, not a deadlock
What works: Embed a duration threshold table directly in the instruction. Before ANY tool call, the agent checks: “Is this actually outside normal bounds?” If not, it reports “expected behavior” and stops immediately.
Tokens saved: Entire investigation (8-12 calls) avoided for false alarms.
4. Anti-Fixation: Is This Error Unique or Fleet-Wide?

The most common agent failure mode: finding an error in the logs and immediately declaring it the root cause — without checking if that same error appears in 500 other healthy systems.
What works: Before declaring any finding as root cause, widen the query scope. Remove the entity filter and check fleet-wide count.
Finding: "uuid mismatch" error in logs
→ Widen: same error in how many other entities?
→ 47 other entities have it → SYSTEMIC NOISE, not root cause
→ Only this entity has it → HIGH CONFIDENCE signalCritical rule: Only validate the LEADING HYPOTHESIS. Don’t burn a tool call validating every intermediate finding.
Research basis: This is the AIOps equivalent of mABC’s (CAS+Tencent, 2024) weighted voting. An error that’s unique to your entity is high-weight evidence. An error that’s everywhere is zero-weight.
5. Know When You Don’t Know
PACE-LM (Microsoft, FSE 2024) proved that LLM confidence is poorly calibrated. An agent that always produces a diagnosis — even when evidence is thin — will be wrong often enough to erode trust.
What works: An explicit “I don’t know” output path that’s MORE VALUABLE than a wrong guess.
### Investigation Incomplete
**What I confirmed:** [facts with high-trust evidence]
**What I ruled out:** [hypotheses eliminated and why]
**What remains unclear:** [specific unknowns]
**Suggested next steps for human:**
1. [specific thing to check that I couldn't]
2. [team to engage and what to ask them]
A wrong diagnosis wastes hours. An honest “I checked X, Y, Z — here’s what a human should look at next” saves time and builds trust.
The Missing Half: Domain-Smart vs Methodologically Rigorous
After building the first version of our troubleshooting agent with embedded diagnostic tables, triage gates, chain tracing, and escalation paths — it was domain-smart but methodologically weak. It knew what to check for every stuck state. But it would jump to the first plausible finding, declare it root cause, and stop. No second opinion. No attempt to disprove. No structured evidence trail.
Then we studied a scientific investigation methodology that was the exact opposite — methodologically rigorous but domain-blind. It enforced multiple hypotheses, falsification, evidence ledgers, and adversarial self-review. But it had zero domain knowledge. It couldn’t tell you that a host in FW_UPGRADE for 30 minutes is normal, or that is_permitted: false is expected during Phase 4.
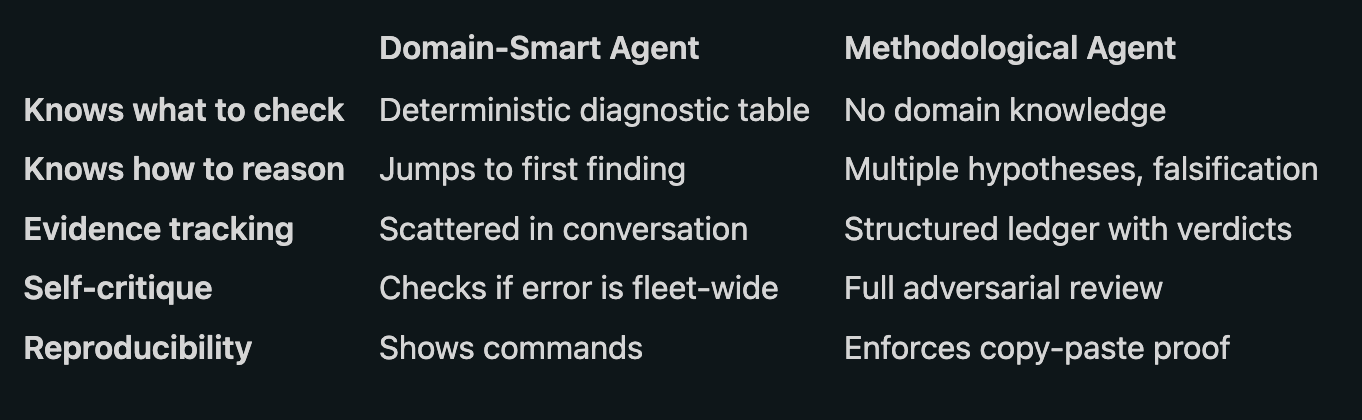
The real insight: these aren’t competing approaches — they’re complementary halves. The diagnostic table gives you the first hypothesis (H1). The scientific method forces you to form a second hypothesis (H2) and attempt to disprove H1 before confirming it. Domain knowledge tells you WHERE to look. Methodology tells you HOW to reason about what you find.
The merged result: an agent that uses the diagnostic table to start fast (no wasted KB queries for the 80% case), but applies rigorous methodology to avoid the confirmation bias trap that makes single-hypothesis agents unreliable.
The Scientific Method: Multiple Hypotheses and Falsification
The single biggest improvement to any troubleshooting agent comes from applying the scientific method. Most agents jump to the first plausible explanation and stop. This leads to confirmation bias — the agent finds evidence that supports its initial guess and ignores everything else.
What works: Force the agent to form at least two hypotheses before testing, and require it to attempt to disprove its leading hypothesis before declaring it confirmed.
Diagnostic table says: "Host stuck in READY → check Phase 4 gates"
H1: Phase 4 gate is blocking (most likely)
H2: Host has a hardware issue preventing boot (alternative)
Test H1: Splunk shows WaitForDns repeating → supports H1
Test H1 (falsification): Is this DNS failure unique to this rack?
→ Yes, only this rack → H1 still holds
Test H2: BMC shows power on, SEL clean → contradicts H2
H1 CONFIRMED, H2 REJECTED. Root cause: DNS gate failing.
The key is that falsification attempt — “Is this DNS failure unique?” If 50 other racks have the same DNS error, H1 is actually wrong — it’s a systemic issue, not a rack-specific one.
Five hard rules that make this work:
No conclusion without evidence — every conclusion cites specific evidence entries
No single-hypothesis investigations — minimum two hypotheses formed
Falsification before confirmation — attempt to disprove before declaring confirmed
Adversarial review before presenting — argue against your own finding
Reproducible proof required — at least one copy-paste command in the report
The Evidence Ledger: Structured Tracking
Most agents scatter their findings across conversational text. When you ask “what did you check?”, it’s buried in paragraphs of reasoning. The evidence ledger fixes this — a structured table tracking every piece of evidence with a verdict against each hypothesis.
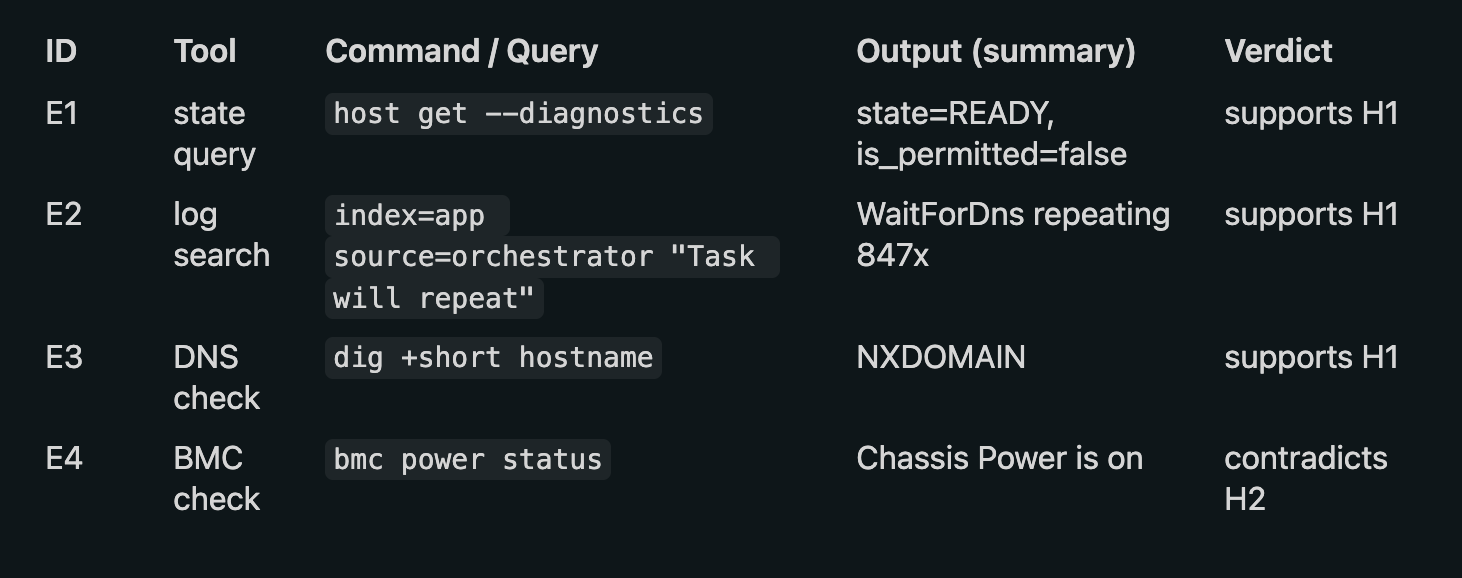
Why this matters:
Every claim traces back to a specific evidence entry (E1, E3, etc.)
The “verdict” column forces the agent to explicitly state whether evidence supports or contradicts each hypothesis
The ledger is auditable — a human can verify every step
When presenting results, the agent cites “per E1, E3” instead of vague claims
Adversarial Self-Review: Arguing Against Your Own Conclusion
Anti-fixation (checking if an error is fleet-wide) is a subset of a more powerful technique: adversarial self-review. Before presenting any conclusion, the agent must construct the strongest counter-argument.
Adversarial review:
Conclusion: DNS gate is blocking the rack (E1, E2, E3)
Counter-argument: Could this be a transient Infoblox issue
that will self-resolve?
Rebuttal: E2 shows the gate has been repeating for 847 iterations
over 3 days. Transient issues resolve within hours. Also, E3 shows
the DNS record was never created (NXDOMAIN), not that it's timing
out. This is a permanent configuration gap, not a transient failure.
Counter-argument sufficient? NO — conclusion stands.
This catches the most insidious failure mode: when the agent finds the right symptom but declares the wrong root cause because it stopped one step too early.
The Evidence Weighting Hierarchy
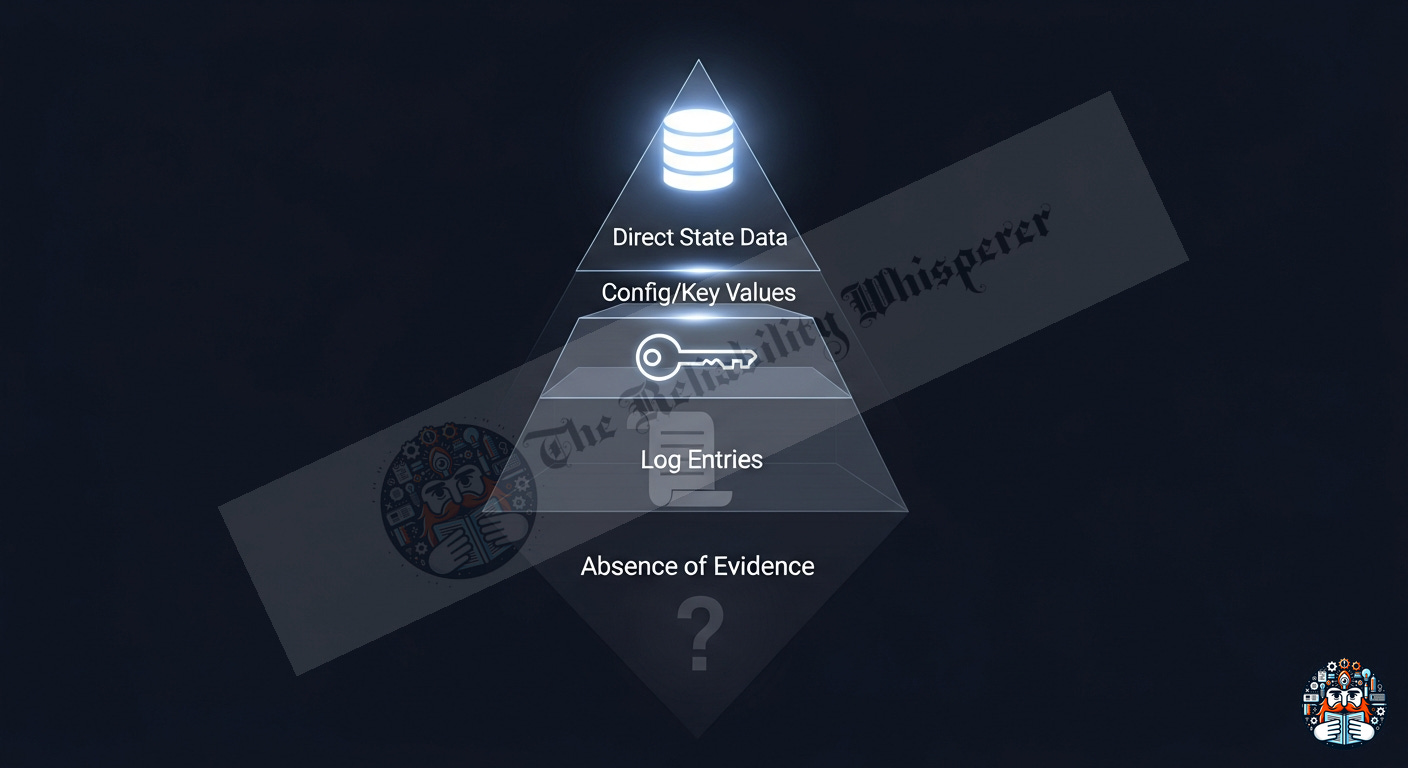
Not all data sources are equally trustworthy. The agent must weight its confidence accordingly:

Key rules:
A state query that CONFIRMS > 10 log lines that SUGGEST
If logs contradict state data, trust state (logs can be delayed/stale)
“No results found” is NOT evidence of absence — the query may be wrong
Multiple independent sources agreeing = HIGH confidence (corroboration)
The Wrong Action Guard
A troubleshooting agent that recommends the wrong remediation is worse than no agent at all.
What works: Embed a “never recommend” table that catches common mistakes:

The agent must verify prerequisites before recommending any action, and it must never execute write operations — only suggest them for the human to run (the copilot pattern).
Circuit Breaker: Preventing Infinite Investigation
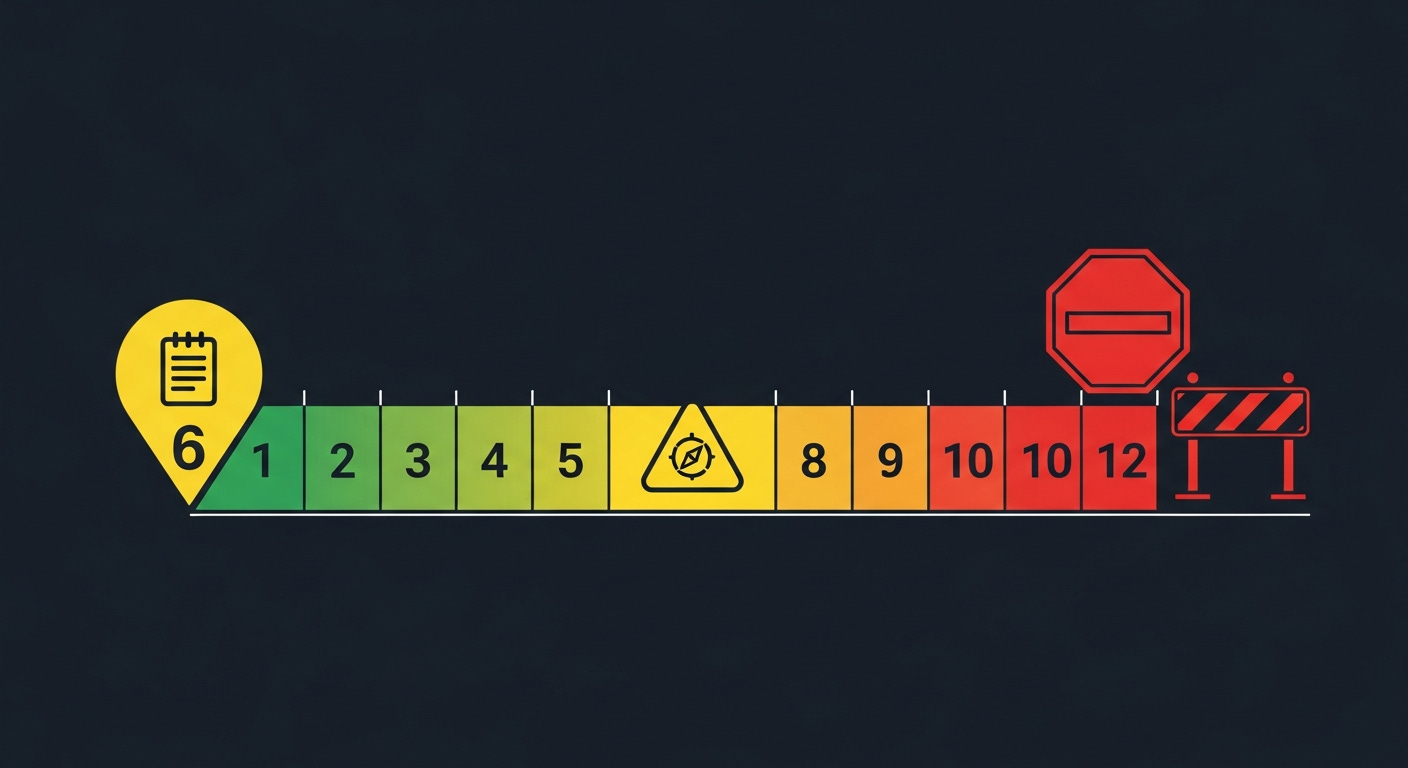
IBM Research (2024) found that agent coherence degrades after 10 reasoning steps. Without a hard stop, agents drift into rabbit holes — investigating tangentially related subsystems that have nothing to do with the original problem.
Three-checkpoint design:
Tool call #6 ──▶ Findings checkpoint (summarize what's known so far)
Tool call #8 ──▶ Coherence self-check ("Am I still investigating the original problem?")
Tool call #12 ──▶ Hard stop — present findings or use "I don't know" path
The coherence check at step 8 is critical. The agent literally asks itself: “Can I connect my current line of investigation back to the original symptom?” If not, it returns to the original problem and tries a different angle.
What Consistently Fails

Implementation Checklist
If you’re building a troubleshooting agent, here’s the minimum viable design:
Architecture:
Single agent with direct tool access (not multi-agent loop)
Triage gate with duration thresholds and false alarm patterns embedded
Deterministic diagnostic table (state → first check — no KB call needed)
Knowledge base fallback for novel/rare cases (service-specific queries)
Dependency chain tracing in the instruction (not flat checklist)
Wrong action guard table (never recommend these)
Copilot pattern — suggest, never execute
Scientific Method:
Minimum two hypotheses before testing (diagnostic table gives H1, form H2)
Evidence ledger — structured table tracking every tool call with verdict per hypothesis
Falsification before confirmation — attempt to disprove before declaring confirmed
Adversarial self-review — argue against own conclusion before presenting
Reproducible proof — at least one copy-paste command in every report
Anti-hallucination rules — cite evidence IDs, never fabricate, flag assumptions
Guardrails:
Evidence weighting hierarchy (state > logs > absence)
Anti-fixation check before declaring root cause (is it fleet-wide?)
Coherence self-check at step 8
“I don’t know” path with structured partial report
Circuit breaker at 12 tool calls
Engagement levels — let user choose oversight (autonomous / collaborative / guided)
Conclusion
The gap between demo and production for troubleshooting agents isn’t intelligence — it’s discipline. The LLM is smart enough to diagnose most issues. What it needs is:
Domain knowledge embedded where it saves calls (not queried every time)
Guardrails that prevent common failure modes (fixation, wrong actions, rabbit holes)
Honest uncertainty (knowing when to stop and hand off to a human)
Efficiency (12 targeted tool calls > 50 unfocused ones)
The single-agent, knowledge-first, chain-tracing architecture handles 80%+ of real incidents directly — and gracefully escalates the rest. That’s not perfect autonomy. That’s a useful copilot. And right now, that’s what actually ships.
